

In questo articolo riporto un caso studio di uno sviluppo su BW4HANA sfruttandone le funzionalità della virtualizzazione del dato e delle calculation view e confrontarlo alle possibili soluzioni alternative che si sarebbero dovute implementare su un BW7.
È un articolo molto lungo che può essere visto come:
- una guida step by step su come impostare un modello virtuale,
- Una guida su come creare delle calculation view
- un esempio pratico di come gestire tutte le fasi di un progetto
- come effettuare le analisi del caso
- un approfondimento sulle differenze implementative tra BW4HANA e il BW7
Scenario
Il caso studio di oggi è parte di un progetto che sto seguendo in prima persona come consulente SAP BW in una importante realtà che si occupa di utility (nello specifico gestione del servizio elettrico, idrico e di raccolta dei rifiuti) nel Nord Italia.
Le utility utilizzano un modulo SAP per il transazionale che è ISU. Questo modulo, sebbene poco conosciuto da molti addetti ai lavori, è estremamente completo per la gestione specifica del business della vendita (e trasporto) di servizi legati all’energia elettrica, gas, idrica e alla gestione e la raccolta dei rifiuti.
Ha delle particolarità molto importanti rispetto ad altri moduli SAP ed è molto complesso soprattutto nella gestione del processo di fatturazione.
Fatturazione in SAP IS-U
Pensa per un attimo alle bollette che ti arrivano a casa (o via web) per la corrente elettrica.
Hanno diverse componenti di consumo (con prezzi differenti), fasce orarie, componenti fisse come ad esempio gli oneri fiscali, hanno una cadenza che dipende dal tipo di cliente – solitamente bimestrale per le famiglie e mensile per le grandi aziende ma esistono anche casi in cui è semestrale o annuale- e questa cadenza di fatturazione dipende in buona sostanza da quale giorno del mese si è attivato il contratto.
Mi soffermo ancora un attimo sulla complessità del sistema di fatturazione ISU perché il caso studio verte proprio su una modifica al relativo flusso in BW4HANA.
Di seguito riporto un esempio parziale di fattura ISU per capire la quantità di informazioni e di righe presenti a sistema per ogni fattura che viene emessa:
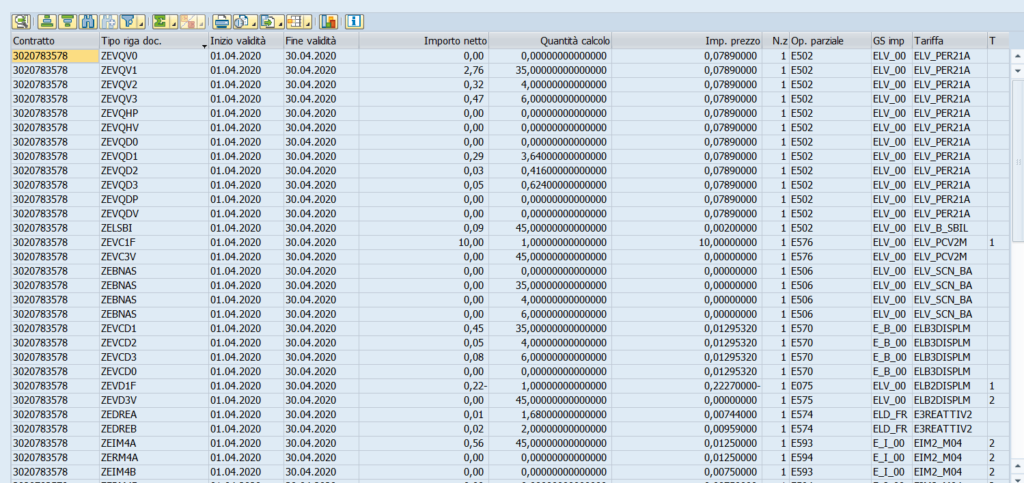
Ognuna di queste righe ha un periodo di competenza associato – questo è importante per capire a pieno il contesto di riferimento del caso studio – che potrebbe essere differente rispetto alle righe successive perché ad esempio ci sono delle righe di conguaglio.
Il periodo di competenza riporta semplicemente l’indicazione di quale periodo temporale è stato considerato per la riga di interesse ed è importante perché le bollette vengono emesse in un momento successivo rispetto ai consumi che sono sostenuti.
Fatta questa doverosa panoramica iniziale possiamo addentrarci meglio nel caso studio di oggi.
Requisito da implementare
Lo sviluppo da implementare consisteva nell’aggiungere un’informazione legata agli operandi al fatturato di una azienda di utility.
Se non sai cosa siano gli impianti, tranquillo ora te lo racconto
Ma prima vorrei focalizzare l’attenzione su alcuni punti importanti delle due righe scritte in precedenza.
A prima vista sembrerebbe uno sviluppo molto semplice (si potrebbe dire che si tratta di una select), ma ci sono delle cose a cui fare attenzione.
Mole dati molto importante
La prima e sicuramente più immediato punto di attenzione è relativo alla enorme mole dati delle strutture su cui dovevamo intervenire.
L’aDSO di primo livello del fatturato conta circa 8 miliardi di righe.
Questo è un valore assolutamente enorme, a maggior ragione se pensiamo che vengono tenuti in linea solo gli ultimi 2 anni.
Lo ripeto, 2 anni di dati corrispondono a 8 miliardi di record
E questo è un dato che bisogna considerare se si pensa di voler fare una ripresa dati.
Analisi funzionale sugli operandi
Ok a questo punto possiamo capire in cosa consiste effettivamente la richiesta.
Per farlo è necessario fare un breve excursus funzionale sugli operandi. Gli operandi sono degli “attributi” dell’impianto e servono a dare diverse informazioni rilevanti per la fatturazione come ad esempio la periodicità di fatturazione o se si tratta di un monorario o di un contratto a fasce orarie per la corrente elettrica (quest’ultima è proprio l’informazione che ci era stato richiesto di inserire nella reportistica del fatturato).
Le informazioni relative agli operandi hanno una dipendenza temporale, il che vuol dire che hanno una data di inizio e fine validità perché nel tempo potrebbero cambiare valore. Quindi per inserire il corretto valore dell’operando sulla riga del fatturato è necessario che il periodo di competenza della riga del fatturato sia compreso nelle date di validità dell’operando. In altre parole se ho una fattura (o meglio una delle righe della fattura) che si riferisce al mese di maggio 2020 dovrò leggere il valore dell’operando che era attivo in quel periodo.
Ci sono un altro fattore a cui prestare attenzione evidenziato in fase di raccolta del requisito.
Bonifiche retro-attive
È possibile che il valore dell’operando subisca variazioni retro attive (ossia che ad esempio nel maggio del 2020 si cambi il valore che l’operando doveva assumere a gennaio 2020). E questo è un aspetto che si rivelerà determinante in fase di determinazione del modello dati.
Profondità storica
Ultimo aspetto da non sottovalutare è che il è necessario riportare queste informazioni anche per l’anno già concluso (ossia il 2019). Questo è molto importante e si collega alla mole dati del flusso in quanto non potevamo prendere in considerazione la possibilità di iniziare ad inserire tale informazione dal momento dello sviluppo ma dovevamo recuperare un dato pregresso (quindi già scritto sul flusso stesso).
Ricapitoliamo il requisito funzionale:
Ci è stato chiesto di aggiungere l’informazione del valore di un operando specifico sulle righe del fatturato.
Gli operandi devono essere letti con una dipendenza temporale
Il valore dell’operando può variare in maniera retro attiva.
La profondità storica minima è di un anno prima rispetto all’inizio degli sviluppi
Analisi tecnica del requisito
Ok abbiamo il nostro requisito funzionale, è tempo di condurre un’analisi tecnica per poter individuare il corretto modelli dati da implementare.
Ognuno dei principali punti del requisito funzionale svolgerà un importante ruolo nella determinazione del modello dati da implementare e per questo riporto il requisito e seguito dall’analisi tecnica che ne è conseguita.
- Gli operandi devono essere letti con una dipendenza temporale
Questo implica che la lettura non può essere eseguita con una select o una join secca ma si deve tener conto delle date => per un modello virtuale bisogna creare una join a dipendenza temporale
2.Il valore dell’operando può variare in maniera retro attiva.
Se viene effettuata una bonifica retro attiva sull’operando è necessario che questo cambio venga recepito sul fatturato. E qui si aprono due tematiche importanti:
- Gli operandi devono avere aggiornamenti in full (almeno una volta a settimana)
- Non possiamo pensare di scrivere l’informazione del fatturato sull’aDSO (di tipo cubo) del fatturato perché altrimenti bisognerebbe prevedere dei ricicli del fatturato periodici per gestire tali aggiornamenti. Questo produrrebbe un grande ritardo nell’aggiornamento del dato a seguito della bonifica ma soprattutto un enorme problema di performance a causa dell’enorme mole dati
3. La profondità storica minima è di un anno prima rispetto all’inizio degli sviluppi
Questo implica che se volessimo gestire il modello scrivendo l’informazione sul fatturato sarebbe necessario pensare ad una ripresa dati di almeno un anno di fatturato ossia di circa 4 miliardi di record => questo porta alla conclusione che non è possibile pensare ad un modello in cui si scrive (e quindi storicizza) il valore sul fatturato ma è necessaria una soluzione virtuale
Punti di attenzione che mi hanno portato a pensare alla virtualizzazione del dato
L’analisi tecnica ha evidenziato problemi che non erano affiorati ad una prima analisi funzionale (come sempre).
Avevamo di fronte una struttura con 4 miliardi di record per ogni anno, quindi era impensabile fare una ripresa dati iniziale per portare le informazioni dell’operando sui record dell’anno precedente.
Come se questo problema non bastasse, era necessario gestire le eventuali riprese in maniera continua per aggiornare i dati in caso di bonifiche sugli operandi. Il che voleva dire che andava programmata una ripresa (o meglio un lookup) dei dati del fatturato periodicamente.
Questo era impensabile perché per elaborare circa 4 miliardi di record avremmo avuto problemi legati a:
- Tempo macchina di elaborazione di qualche giorno ogni volta che veniva eseguito il calcolo
- Di conseguenza non si sarebbe potuto aggiornare il fatturato nei giorni in cui veniva eseguito tale lookup
- Il fatturato è storicizzato in un aDSO di tipo cubo e pertanto gli indici vanno in somma. Questo implica che nel riciclo dei dati si doveva tener conto di questa somma degli indici per non duplicare il fatturato ad ogni giro
- Un effort per la macchina insostenibile con il rischio di tirare giù il sistema produttivo ad ogni riciclo.
Tutte queste osservazioni mi hanno portato a pensare che l’unica soluzione fosse quella di non storicizzare alcun dato ma gestire tutti gli aggiornamenti virtualmente tramite apposite join.
Punti di attenzione sul modello virtuale
Ovviamente anche la soluzione aveva dei punti di attenzione che erano legati principalmente a come eseguire le join con dipendenza temporale e le performance finali del modello.
Join a dipendenza temporale
Questo aspetto è molto importante e la scelta dello strumento corretto per risolvere il problema è fortemente condizionata dal fatto che tale dipendenza temporale non poteva essere eseguita mediante una condizione di uguaglianza ma tramite un range.
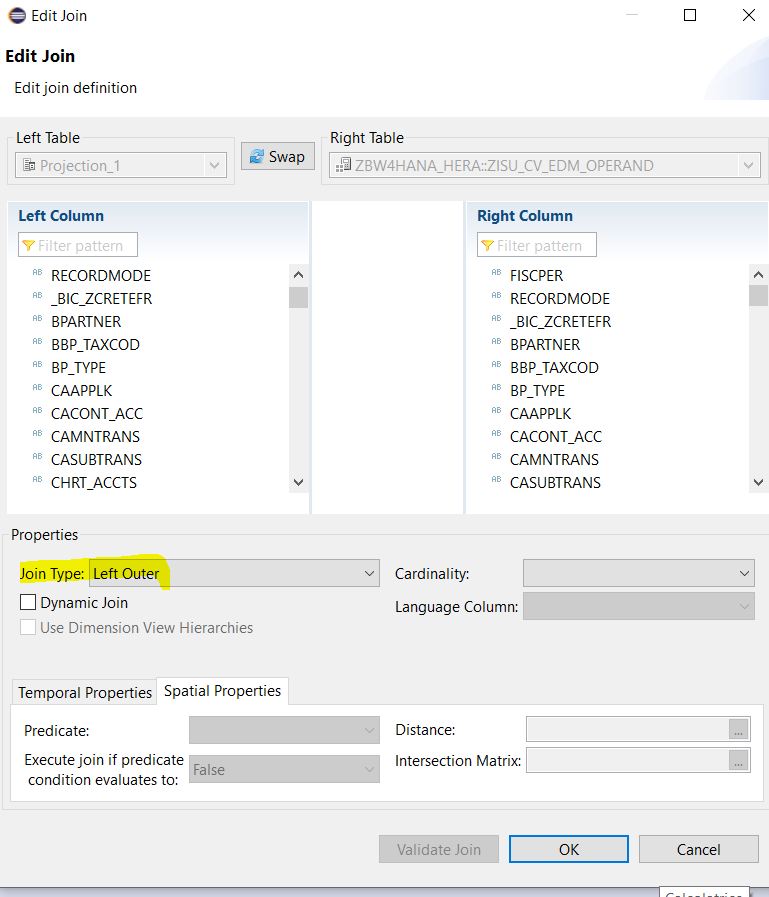
La condizione di join era :
il periodo di competenza della riga del fatturato sia compreso nelle date di validità dell’operando
Abbiamo scelto di considerare la fine del periodo di competenza del fatturato in quanto l’estrattore standard del fatturato crea una riga per ogni mese di competenza. Ma questa data doveva essere compresa in un intervallo.
Questo aspetto ha di fatto scartato la possibilità di utilizzare un composite provider in quanto in quel caso le uniche condizioni di join ammesse sono di uguaglianza.
L’unica possibilità rimanente era quella della calculation view.
Performance di un modello virtuale con oltre 4 miliardi di dati
Il secondo aspetto da prendere in considerazione in un modello virtuale è legato alle performance ossia al tempo di elaborazione dei calcoli.
Nello scenario classico di BW si hanno delle catene che eseguono dei caricamenti in maniera asincrona rispetto a quando si lancia il report. Questo vuol dire che la notte – solitamente – avvengono dei caricamenti che scrivono fisicamente il dato nelle tabelle dei vari aDSO e quindi i tempi di elaborazioni del dato vengono spostati a quel momento. Pertanto quando l’utente lancia il report di fatto vede dati già pronti ed elaborati e quindi non ci sono tempi di attesa.
Nel caso di modelli virtuali questo non avviene in quanto tutti i calcoli, o perlomeno quelli eseguiti virtualmente, vengono effettuati nel momento stesso in cui l’utente lancia il report.
La tecnologia Hana su cui si basa BW4HANA ha fortemente ottimizzato tali tempistiche e quindi tendenzialmente questi calcoli vengono eseguiti in pochissimi secondi se non frazioni di secondo.
Un modello virtuale ha senso proprio grazie a questa potenza di calcolo.
Tuttavia in un contesto in cui avevamo da una parte il fatturato con 8 miliardi di dati (2 anni) e dall’altro gli operandi (circa 400 milioni di record) le tempistiche potevano diventare molto problematiche.
Da ciò la considerazione di dover filtrare quanto più possibile i dati.
Esistevano dei filtri fissi impostabili a monte dell’elaborazione come ad esempio l’operando di interesse e le società del gruppo per cui era di interesse tale calcolo.
Ma questi filtri non erano sufficienti perché i parametri più importanti non erano prevedibili a priori in quanto dipendono dalle analisi che deve effettuare il business, come ad esempio il mese di competenza di interesse.
Era necessario impostare dei filtri dinamici in grado di filtrare la base dati prima di eseguire i calcoli in base ai parametri utilizzati al lancio della query.
La soluzione era quella di utilizzare delle calculation view con degli input parameter
Fra poco spiego cosa sono e come si utilizzano. È finalmente ora di andare a vedere passo per passo il modello implementato.
Soluzione implementata con le calculation view e i composite provider
Finalmente abbiamo finito tutte le nostre analisi e possiamo disegnare il nostro modello dati.
Bene abbiamo detto che:
- Realizzeremo delle calculation view
- Dobbiamo essere in grado di fare join time depending con dei range
- La fase di ottimizzazioni delle tempistiche è fondamentale.
Vediamo il modello dati nel complesso.
Filtri fissi e dinamici per tagliare a monte i dati
Partiamo con il primo aspetto da tenere in considerazione, ossia i filtri da impostare.
Abbiamo detto che abbiamo filtri fissi a monte applicabili sia sul fatturato che sugli operandi. Bene questi vanno applicati subito per essere certi di delimitare il set di dati. Poi capiremo come inserire invece i filtri dinamici
Attribute view per impostare i filtri fissi
Creiamo una attribute view (che di fatto è un tipo di calculation view) :
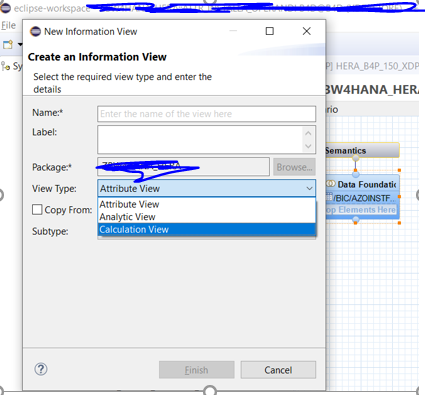
in cui semplicemente richiamiamo la tabella BW (ossia la tabella dei dati attivi dell’aDSO di interesse) e impostiamo i filtri che ci interessano:
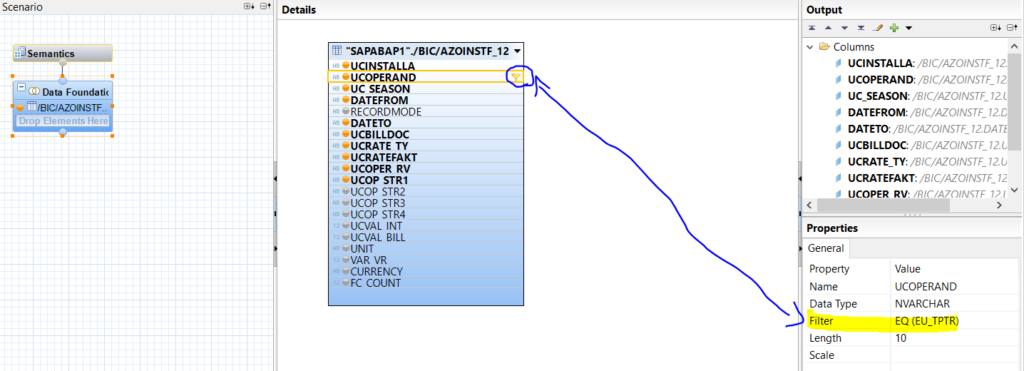
Input Parameter: input dinamici
Passiamo ora ad una funzione che mi ha permesso di salvare le performance di questo report e salvarmi da un modello dati complesso ed oneroso: gli input parameter.
In SAP HANA, gli input parameter (parametri di input) vengono utilizzati per filtrare i dati passando un input dall’utente ed eseguire calcoli aggiuntivi in fase di esecuzione. I dati vengono recuperati in base al valore di input, quando viene eseguita una vista. Fantastico, quindi l’utente immette un parametro di lancio nella query e questo viene utilizzato per selezionare i dati su cui eseguire i calcoli:

Ed ecco come parametrizzarli:
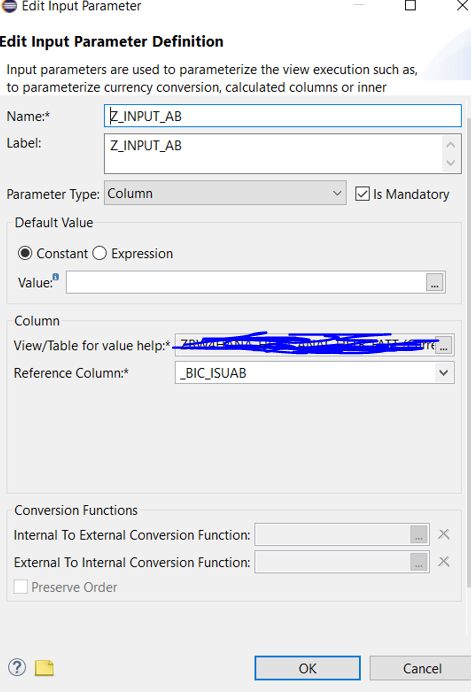
Dove la spunta su “mandatory” sta ad indicare che è un parametro che deve essere valorizzato per forza da parte dell’utente.
Il tipo di parametro “Column” invece permette di associare tale filtro ad un oggetto che nel nostro caso è il campo AB (ossia l’inizio competenza). Ovviamente questi filtri vanno propagati ad ogni CV (calculation view) successiva rispetto a quella appena creata, al composite in cui la calculation view verrà esposta e nella query. Nei prossimi paragrafi spiegherò come farlo
Come propagare un input parameter in una Calculation View
Abbiamo creato la nostra analytic view in cui abbiamo impostato gli input parameter sul fatturato.
Ora il nostro obiettivo è quello di mettere in join questa informazione con l’attribute view che abbiamo creato sugli operandi.
Creiamo una nuova CV in cui effettuiamo la join (per questo punto vedere i paragrafi successivi) e finalmente possiamo “far salire” gli input parameter dall’analytic view.
Nella nostra join andiamo a filtrare i campi che dovranno risentire del filtro:

Ci posizioniamo su Semantics, a questo punto apriamo il tab Parameters/Variables e quindi propaghiamo gli input che avevamo creato precedentemente.
Nello screen tutti i dettagli:
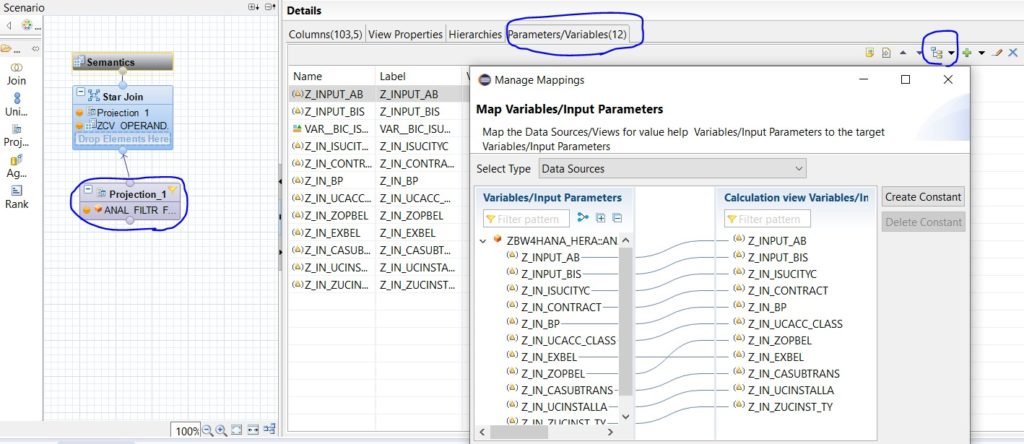
Ok abbiamo salvaguardato le performance. Il risultato finale è stupefacente.
Grazie agli input parameter si riescono ad effettuare join con 4 miliardi di dati in meno di un minuto di elaborazione
Avete letto bene, dal momento in cui l’utente inserisce i parametri di lancio della query e la esegue, al momento in cui il report è pronto passa meno di un minuto e restituisce un mese di competenza di fatturato con l’indicazione dell’operando.
Ma la cosa è ancora più interessante se pensiamo a tutte le elaborazioni che il modello fa e che vedremo nella parte finale di questo articolo.
Input parameter nel composite provider
Ma torniamo a noi, abbiamo impostato i nostri filtri e le nostre CV sono pronte (in realtà manca ancora qualcosa ma lo scoprirai nei prossimi paragrafi). È ora di riportare questi dati su BW e quindi di esporre la nostra CV in un composite.
Farlo è davvero semplicissimo perché basta creare un composite e richiamare il nome della CV di interesse al suo interno:

Ora ci basterà trascinare con il drag e drop gli input parameter:
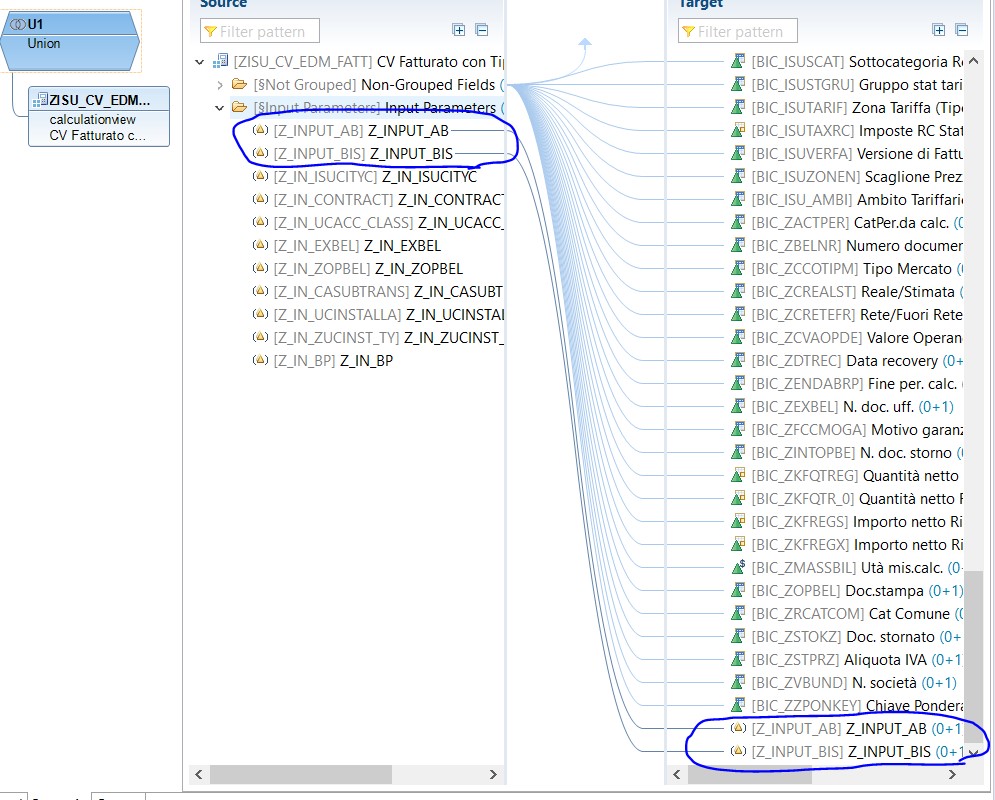
A questo punto basterà associarli all’infobject di interesse per poter poi creare delle variabili pop-up nella query:
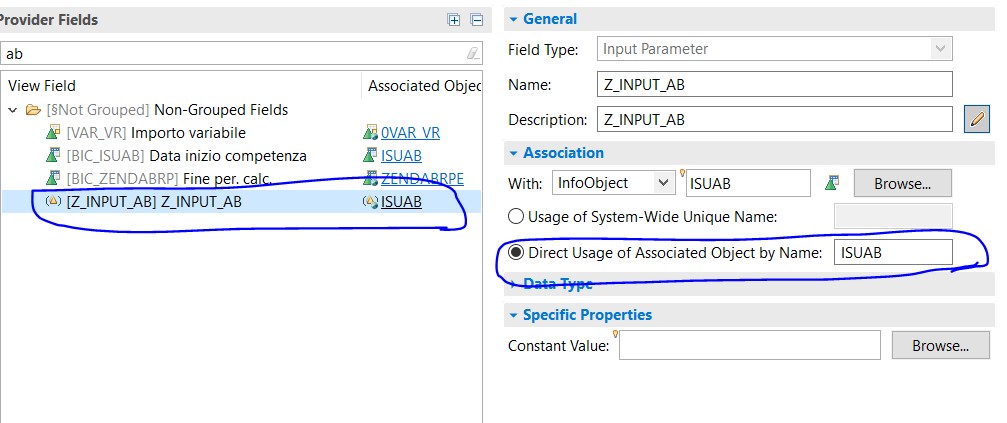
Input parameter in una query
Ecco lo step finale del lungo viaggio dei nostri filtri. Dobbiamo inserirli in query e permettere così all’utente di inserire i parametri di input:
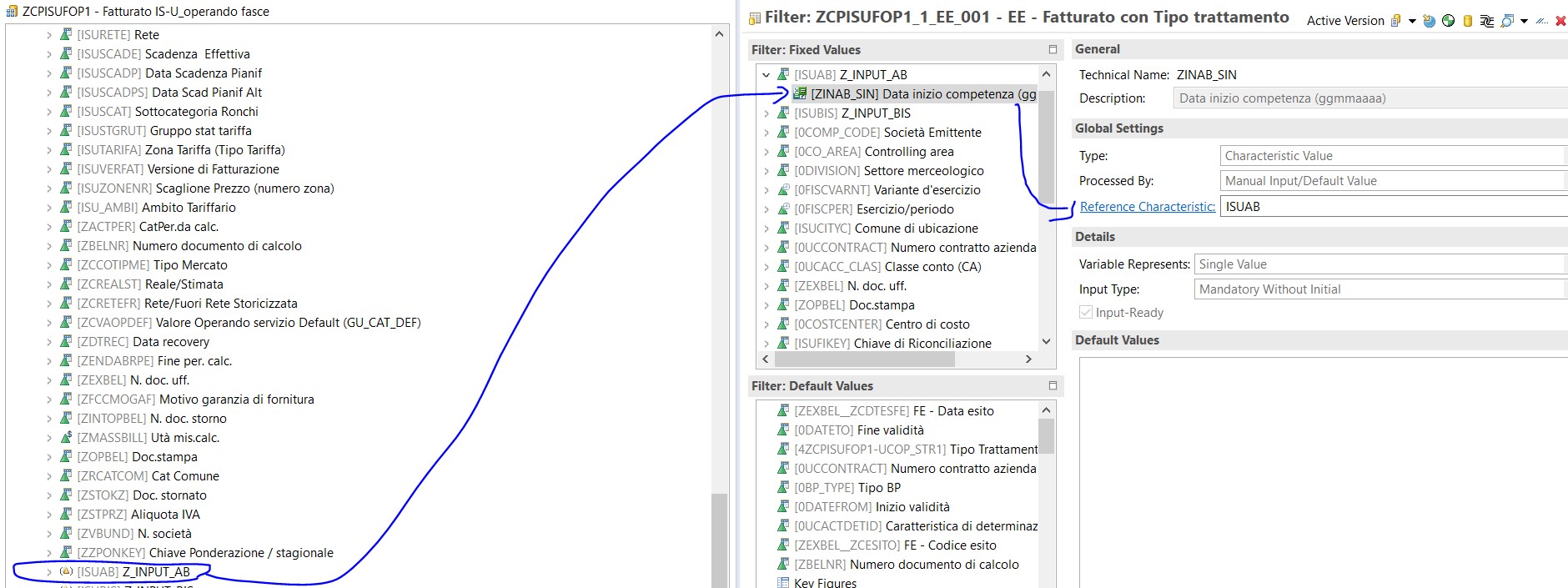
Ed ecco il nostro filtro in query:
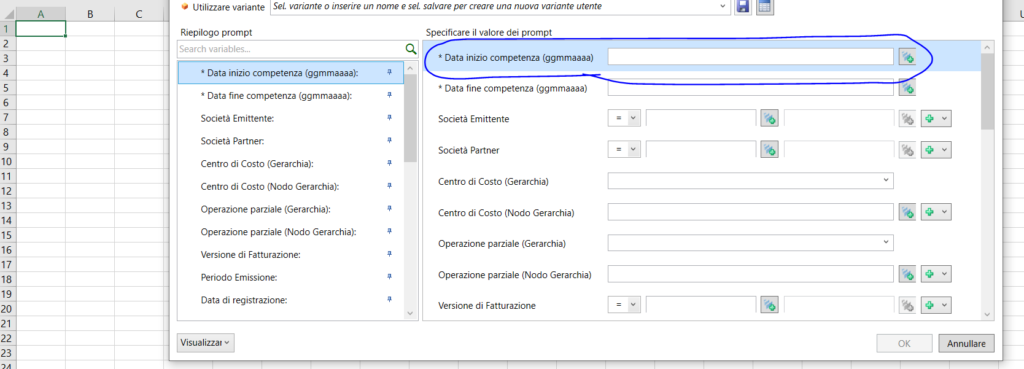
Join a dipendenza temporale con i range
Manca un ultimo dettaglio nel nostro modello.
Quando abbiamo visto come propagare l’input parameter nella CV ho velocemente detto di creare la CV con la join. Ma qui in realtà bisogna fare molta attenzione.
Per usare range per join a dipendenze temporali bisogna utilizzare Star join perché sono le uniche che permettono di inserire delle condizioni con un range (invece della condizione di uguaglianza).
Calculation view con star join
Creiamo la nostra calculation view:
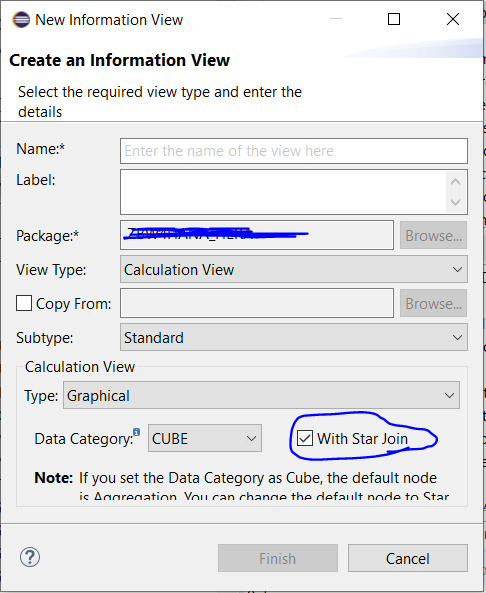
Basta inserire il flag cerchiato nello screen per inserire la star join.
NB.Una volta creata la calculation view non è più possibile modificarne la tipologia
A questo punto richiamiamo le tabelle di interesse e creiamo la join:
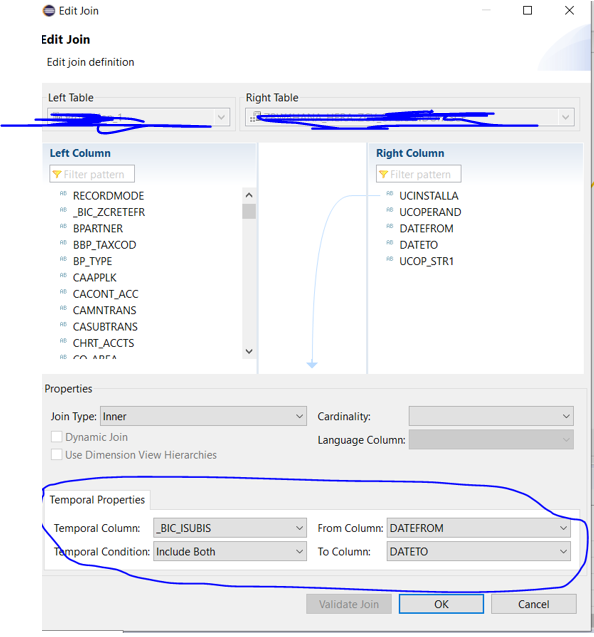
Poi facciamo semplicemente EDIT sulla join:
E possiamo impostare le condizioni temporali come evidenziato nello screen.
Conclusione del modello con la left join
Il modello sembrerebbe finito, ma c’è un ultimo aspetto da tenere bene a mente.
Attenzione perché le star join possono eseguire solamente inner join.
Questo ci ha costretto a rimettere in left join il fatturato con il risultato della star join:
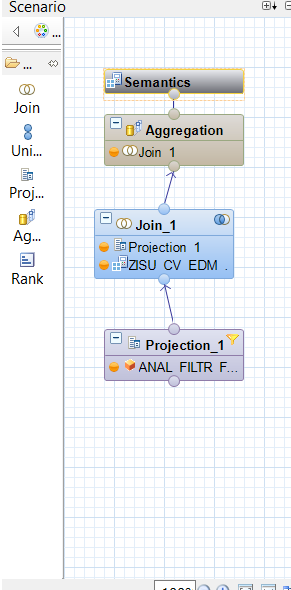
Hai letto bene, abbiamo messo di nuovo in join 8 miliardi di dati con il risultato di questa join perché ci sono dei casi per cui poteva non essere valorizzato tale operando e se non avessimo eseguito questa nuova join avremmo perso dati sul fatturato.
Conclusioni
È incredibile che in meno di 1 minuto il motore di Hana riesce a:
- Passare i filtri che l’utente imputa sulla query alla base dati
- Tagliare i filtri sulla base di quanto inserito dall’utente
- Eseguire una prima inner join con una base dati di 8 miliardi di record eseguendo i confronti temporali
- Eseguire una seconda join tra una base dati di 8 miliardi di dati e il risultato della inner precedente
- Spostare tutte queste informazioni su BW
- Restituire il report all’utente
Ovviamente se i primi due punti non fossero stati eseguiti questo risultato sarebbe stato impossibile in quanto in realtà non vengono elaborati 8 miliardi di dati ma solamente quelli che rispettano i filtri inseriti dall’utente.
Questo lungo articolo riporta un caso studio di uno sviluppo su cui ho lavorato in questi giorni e che mi ha dato la possibilità di dimostrare concretamente la potenza degli strumenti di virtualizzazione messi a disposizione da BW4HANA.
Su un Data wharehouse che non consente di utilizzare tali strategie sarebbe stato necessario creare dei cubi di back up del fatturato in cui effettuare il calcolo dell’operando per tener conto delle bonifiche e poi riportare i dati sul cubo originario.
Ovviamente è possibile pensare ad un modello del genere (e forse è quello che avrei realizzato su BW7) ma presenta un carico macchina enorme, allungamenti immensi dei caricamenti ed importantissime duplicazioni dei dati nel DB.
Spero di non averti annoiato troppo con i tecnicismi dello sviluppo e di essere riuscito a darti informazioni utili. Fammi sapere se questo articolo ti è piaciuto scrivendomi una mail a info@fabianosileo.it e per dirmi se possono interessarti altre guide tecniche come questa.

Sono un consulente di Business Intelligence,lavoro con uno dei software di Business Intelligence più importanti e completi sul mercato che è SAP BW (da poco diventato BW4HANA), e ho avuto modo di lavorare con grandissime realtà nazionali ed internazionali.
In tutte queste realtà ho avuto modo di entrare nella vita aziendale conoscendone i processi, i problemi, e le necessità e di relazionarmi con key user, decision maker, manager e personale operativo per riuscire a costruire report e dashboard che facilitassero il loro lavoro e permettessero in pochissimi click di ottenere tutte le principali informazioni sull’andamento della società.
Ho iniziato a fare divulgazione sul tema Business Intelligence per spiegare anche ai non addetti ai lavori quanto sia importante ragionare sempre in funzione di dati e come sfruttare la tecnologia per prendere decisioni migliori.
Le informazioni hanno un valore inestimabile e sono la cartina al tornasole di qualsiasi business mentre i dati da soli sono solo numeri!






Ciao Fabiano,
mi permetto di darti del tu anche per la tua giovane età. Sono Gianvito Laera e sono un tuo “collega” lavoro a Bologna per KPMG ed ho 40 anni. Mi piace il tuo entusiasmo in ambito BI e ti volevo fare i miei complimenti, è davvero difficile trovare gente che lavora con dedizione e che approccia le tematiche tecniche con un approccio metodologico in Italia al giorno d’oggi.
Ho letto questo tuo ultimo articolo e volevo comunque riportare una considerazione ovvero che il motore hana se il mapping di una campo è linerare dalla sorgente alla destinazione è in grado di spingere verso il basso i filtri applicati a prompt senza dover necessariamente creare un input parameter. Dovresti a riprova di questo lanciare un test con il planviz e così verificare se il filtro applicato a monte si riperquote sino a valle della prima calculation view. Se questo non succede è un problema di interpretazione del dato. Io gli input paramenter gli uso per fare delle condizioni (es. definire i dati intercompany). Quindi creo un input parameter dove ho i due valori e sulla base della scelta filtro direttamente i dati delle intercompany senza così dover duplicare righe, oppure lo uso per la gestione dei cambi valuta e creare i vari currency type.
Fammi sapere cosa ne pensi e se hai bisogno di idee ci possiamo sentire.
Saluti,
Gianvito
Ciao Gianvito,
ti ringrazio sia per i complimenti che per lo spunto.
Farò sicuramente il test che consigliavi e ti ringrazio per il suggerimento, molto puntuale e preciso.
Nel caso specifico avevamo avuto dei problemi nel creare il range senza utilizzare l’input parameter e immagino che sia un problema legato a come viene eseguita la query SQL in fase di estrazione dati.
Ad ogni modo l’approccio di utilizzarli per evitare la duplicazione delle righe è sicuramente molto intelligente e in pienissimo rispetto delle best practies SAP sulla ridondanza dei dati.
Spero di ricevere altri tuoi feedback in futuro altrettanto interessanti
Fabiano